 #carvel in Kubernetes Slack
#carvel in Kubernetes Slack GitHub
GitHubCase Study: Modernizing The U.S. Army to Improve Soldier Well-being
by CReATE Platform Team and Helen George — Oct 14, 2021
How the U.S. Army Software Factory and Enterprise Cloud Management Agency are using Carvel and Cluster API to declaratively manage Kubernetes workloads and clusters in secure air-gapped environments ¶
About ¶
The U.S. Army Software Factory and Enterprise Cloud Management Agency (ECMA) are on a mission to modernize the largest government organization in the United States with the Army’s Code Resource and Transformation Environment (CReATE). Key to this massive modernization effort is building a secure cloud-native application platform where software can be delivered to production across the globe on the most secure networks in the world. These networks span all the way from the cloud to the most denied, disrupted, intermittent, and limited bandwidth environments at the edge. The Army decided to build this platform atop Kubernetes and by adopting DevSecOps throughout their cloud-native software development lifecycle. CReATE is currently leveraged by the greenfield efforts of the Army Software Factory Development Teams – as seen in their work around helping facilitate Soldier well-being, unit cohesion, and improved logistics practices.

Challenge ¶
Consuming and deploying software across highly restricted environments ¶
Almost all of the CReATE’s production environments are highly regulated where non-privileged network access is very limited or non-existent. Additionally, providing CReATE’s platform operators with access into these environments can be complex, either due to physical access to the location or restrictions on granting privileged access. In these environments, both building and consuming software can be a huge challenge and typically requires a lot of human intervention.
This means that it is very hard to get kubectl access and even if you had access to kubectl, it is hard to connect to the internet, either due to firewall restrictions or general connectivity issues.
The Army Software Factory is also enabling Soldiers to develop software applications, and there are other CReATE tenants similarly developing software. By design, these software developers never get access to the production environment: so how do you let developers quickly deploy their apps without giving them direct access to Kubernetes? Answering this question incorrectly can introduce more complexity.
Relocating software efficiently into disconnected environments ¶
CReATE engineers were leveraging custom written scripts and third-party tooling that copied container images between container registries, sometimes using intermediary file storage. The Army realized the tool had been caching image tags and was actually not copying over the most recent container images. Additionally, there was no way to make sure that the Kubernetes manifests being deployed were correctly representing the container images that had been copied over, since the references to the container images were inconsistently populated in values files and only some of them followed a standard pattern.
Managing workloads on many Kubernetes clusters while meeting rigorous compliance requirements ¶
There are two fundamental issues that CReATE platform engineers had to overcome with regards to security and compliance when the team looked to offer DevSecOps capabilities to other Army organizations:
- It can be a lengthy process to make Kubernetes ready for production. How do you manage all of those settings for Kubernetes itself and the additional components when you are providing clusters out to numerous teams in a larger organization? And how do you prevent the teams that might have escalated access from disabling, misconfiguring, or breaking those components?
- For teams that are not as familiar with a Kubernetes operating environment, how do you deploy their software into a Kubernetes space consistently without introducing significant toil to maintaining that software or upgrading it?
In addition to solving these challenges, they had to be done in such a way as to not compromise the flexibility that Kubernetes provides. Users (current and future) expect to be able to scale in size – both in terms of team size and application size. The solutions needed to be able to easily scale to meet these demands.
Solving these problems is already near the bleeding edge for enterprise software development, but when compounded with the naturally and purposefully risk averse compliance process in the DoD the problem looked nearly insurmountable.
Solution ¶
Flexible application delivery automation with kapp and ytt ¶
To answer the question “How do you let developers quickly deploy their apps without giving them direct access to Kubernetes?”, the answer was obvious – automation. But not only automation in the usual sense of scripts and if-this-then-else. Kubernetes lives in a declarative world – specifically, manifests. If you leverage the declarative APIs for everything else in Kubernetes, why not use it to simplify app deployment as well?
kapp-controller is the member of the Carvel toolset that allows developers to easily express their application as an App Custom Resource (App CR). By using a layered approach bundled with additional workflow options like ytt, kbld, and even helm, complex applications can be captured as a simple, top-level manifest file that then lives in a repository, and often an imgpkg bundle or git repo is considered the Source of Truth. kapp-controller will monitor your source of truth and, when a change is detected, will automatically deploy the latest version of your application. This arrangement, the typical infrastructure as code (IaC) combined with the location and means to execute it, is called “Continuous Reconciliation” and is the bedrock of Gitops. The diagram below illustrates this concept.
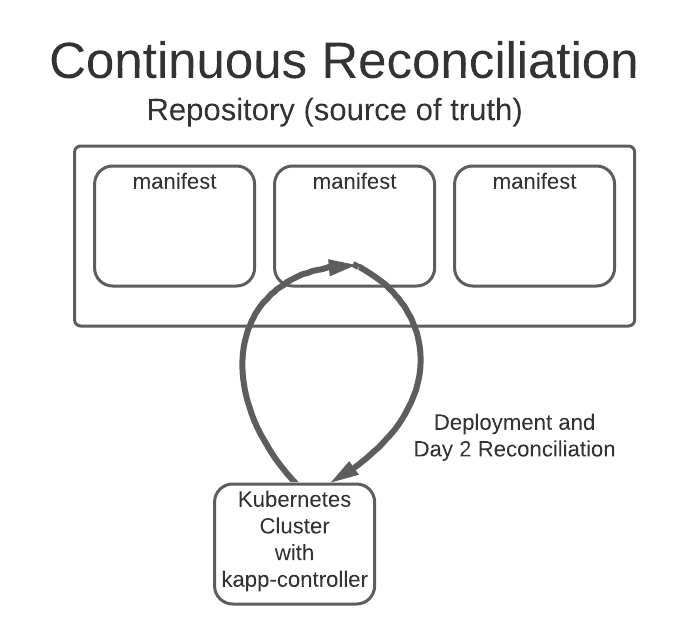
Note: The U.S. Army adopted Carvel prior to the release of the Package Management API and is currently migrating towards it, so a lot of the examples might include references to the App CR which is the underlying technology behind the Package Management API.
With this operating model, the developer only needs to describe their application as an “App”, store it in an imgpkg bundle or git, and then kapp-controller takes care of the work from there. An example app is shown in the code section below. Note the ability to apply templating if it becomes necessary (but is optional!).
# We're defining an App...
apiVersion: kappctrl.k14s.io/v1alpha1
kind: App
metadata:
name: simple-app
namespace: simple-app
spec:
# What service account will run this app?
serviceAccountName: simple-app-svc
# Where is the app coming from?
fetch:
- git:
url: https://gitlab.com/project-awesome/simple-app
ref: origin/master
# We have a directory, named 'app', in the root of our repo.
# Files describing the app (i.e. pod, service) are in that directory.
# That is the directory that kapp-controller will look to for manifests to deploy.
subPath: app
# No templating yet...
template:
- ytt: {}
deploy:
- kapp: {}
By moving the action of deploying an app away from “run these kubectl commands” and up into “modify this version-controlled file in a Git repo”, you remove the need for a developer to run kubectl commands and you meet them where they already are – in their container repository or Git repository.
Also, it enables an operator-driven developer experience where developers can have the modern experience of “I wrote my code locally and it works – I don’t care how you package it and connect services beyond that they are done securely”. This is particularly important for an environment like the Army Software Factory where the range of skills amongst new developers is very wide. Thus a simple flow that operators are able to leverage with ytt and imgpkg was created to establish consistent interfaces for application developers to deploy their applications.
For example if you look at this PostgreSQL deployment model ytt is leveraged to connect applications to the various customers that need the hardened, secure, and highly available PostgreSQL service. By abstracting the App out to a central manifest, it can simply be looped over and instantiated multiple times in a large variety of locations. This model becomes easier to implement when consuming packages.
#! Example data values for ytt
#! List of apps using their own Postgres instances
postgres:
- app-1
- app-2
# Example of iterating over those values to deploy postgres instances for deployments
#@ load("@ytt:data", "data")
#@ for database in data.values.postgres:
---
apiVersion: kappctrl.k14s.io/v1alpha1
kind: App
metadata:
name: #@ "postgresql-ha-{}".format(database)
annotations:
kapp.k14s.io/change-rule.1: "delete before deleting create.army.mil/storageclass"
kapp.k14s.io/change-rule.2: "upsert after upserting create.army.mil/storageclass"
kapp.k14s.io/change-group: "create.army.mil/postgresql-ha"
spec:
#! ...
#@ end
Since the deployment of these applications occurs using kapp, when the manifests are changed and modified, kapp will wait for deployments to upgrade and roll pods, as well as providing user feedback with examples of which parts failed. Additionally, kapp can provide versioning for ConfigMaps and Secrets, this causes modifications to just those files to properly roll pods forward, which would typically not cause a pod to restart. This enables proper zero downtime upgrades for the majority of applications in the environment.
Relocate container images using imgpkg bundle and kbld ¶
Relocation is an area where imgpkg shines. imgpkg’s ability to copy between repositories is leveraged in numerous ways, both to pull base Bitnami published charts and also custom application deployment logic:
# An example of using the copy command to pull images into an area
# where they can be propagated to the protected network
$ imgpkg copy --bundle ${SRC_BUNDLE_LOCATION} --to-repo ${IMGPKG_REGISTRY_HOSTNAME_1}/army/${BUNDLE_NAME}
On its surface this may not seem very powerful, but the magic comes in when you consider what an imgpkg bundle is. imgpkg’s ability to reference additional bundles or container images explicitly allows us to group logical applications like Harbor, Prometheus, PostgreSQL, custom Army applications, and more into logical “bundles” that make it as simple as the one line above to grab the deployment manifests and pull them through. So the command above might have pulled in a dozen helm charts and hundreds of container images; whatever the bundle requires to run properly will get relocated and the references consistently updated. If the container was relocated from another bundle or referenced multiple times in the same bundle, the referenced layers are not duplicated in the underlying storage. In other words, imgpkg will still take full advantage of common base images or commonly reused container images, while creating a simple methodology for teams to pull applications - be they at the Software Factory or in the field at the edge.
For example, a commonly-used application is Envoy. This application is used as a part of tools like Contour and can still be used independently as a separate proxy if desired, but the versions that are supported might be different (as of this blog post Contour 1.19 supports Envoy 1.19, but the latest Envoy is 1.20). So we need to know that Contour will deploy with Envoy 1.19 and we do not just relocate the latest Envoy container image when updating containers.
In short, what you need is to remove ambiguity and not fall victim to accidental image caching. This is addressed by bringing in kbld. kbld is the member of Carvel that creates unique, immutable image references. Consider the usual ‘image:’ line in a manifest file.
image: registry.yourorg.com/envoyproxy/envoy:latest
This line is asking for a specific tag, yes, but that tag can be changed in the registry. Out of malice or mistake, the registry operator can replace that container image with a different one, keep the tag, and you wouldn’t know any difference. kbld solves this by taking that ‘image:’ line above, and giving us a unique, immutable reference, shown below:
image: registry.yourorg.com/envoyproxy/envoy@sha256:ac6a29af5bee160a1b4425d7c7a41a4d8a08a7f9dd7f225f21b5375f6439457a
With this in mind, you can look at the lock file generated by the kbld command:
$ kbld -f https://raw.githubusercontent.com/projectcontour/contour/release-1.19/examples/render/contour.yaml --imgpkg-lock-output sample.yaml
The lockfile can be used to guarantee that the correct references and versions are being pulled in.
---
apiVersion: imgpkg.carvel.dev/v1alpha1
kind: ImagesLock
images:
- annotations:
kbld.carvel.dev/id: docker.io/envoyproxy/envoy:v1.19.1
kbld.carvel.dev/origins: |
- resolved:
tag: v1.19.1
url: docker.io/envoyproxy/envoy:v1.19.1
image: index.docker.io/envoyproxy/envoy@sha256:ac6a29af5bee160a1b4425d7c7a41a4d8a08a7f9dd7f225f21b5375f6439457a
- annotations:
kbld.carvel.dev/id: ghcr.io/projectcontour/contour:v1.19.0
kbld.carvel.dev/origins: |
- resolved:
tag: v1.19.0
url: ghcr.io/projectcontour/contour:v1.19.0
image: ghcr.io/projectcontour/contour@sha256:afa8f57f58a89d164eb1fb004a352ad015273d9fda8cee013c70167d9e5779c0
This workflow is captured in the diagram below.
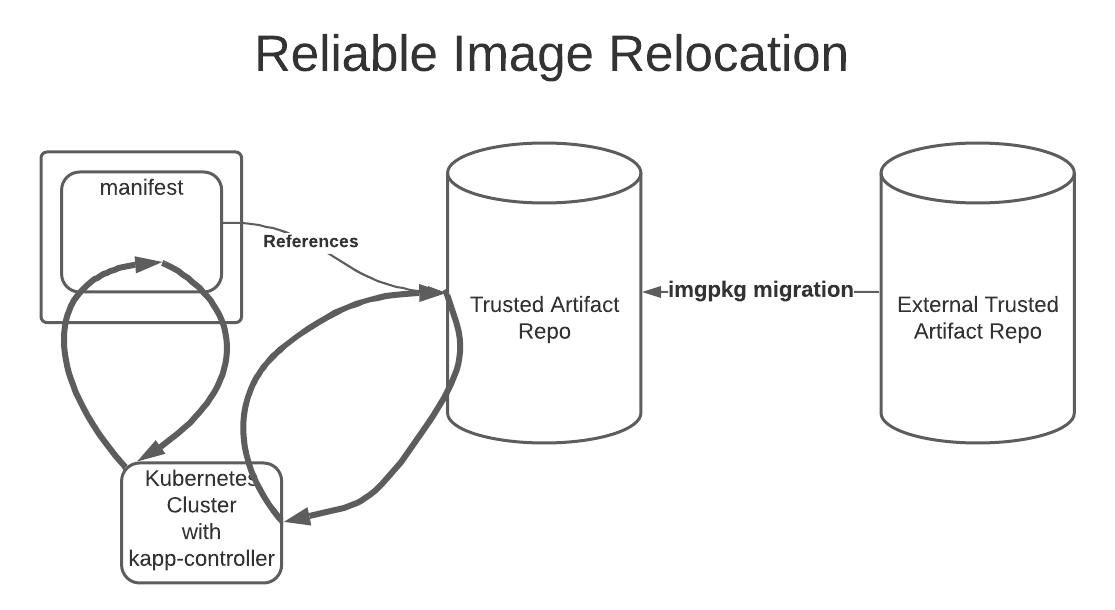
Using imgpkg to concisely bundle your applications, and having kbld give us unique image references, guarantees us that not only are all of the necessary artifacts packaged, but the correct versions of those artifacts are packaged. This removes ambiguity and gives you a high level of confidence in the bundles you use to deploy your applications.
As the Army grew in maturity using imgpkg, we were able to provide references to references, so we could relocate entire catalogs of containers with a single command. imgpkg would correctly traverse each reference and identify container image layers in the process, so that relocation would be minimized to account for our limited bandwidth; each container layer is downloaded and pushed to the new environment only once, even if it is referenced hundreds of times. This allowed many products, including ones like Contour and cert-manager, to have multiple versions synchronized into our environment without increasing the transfer bandwidth significantly.
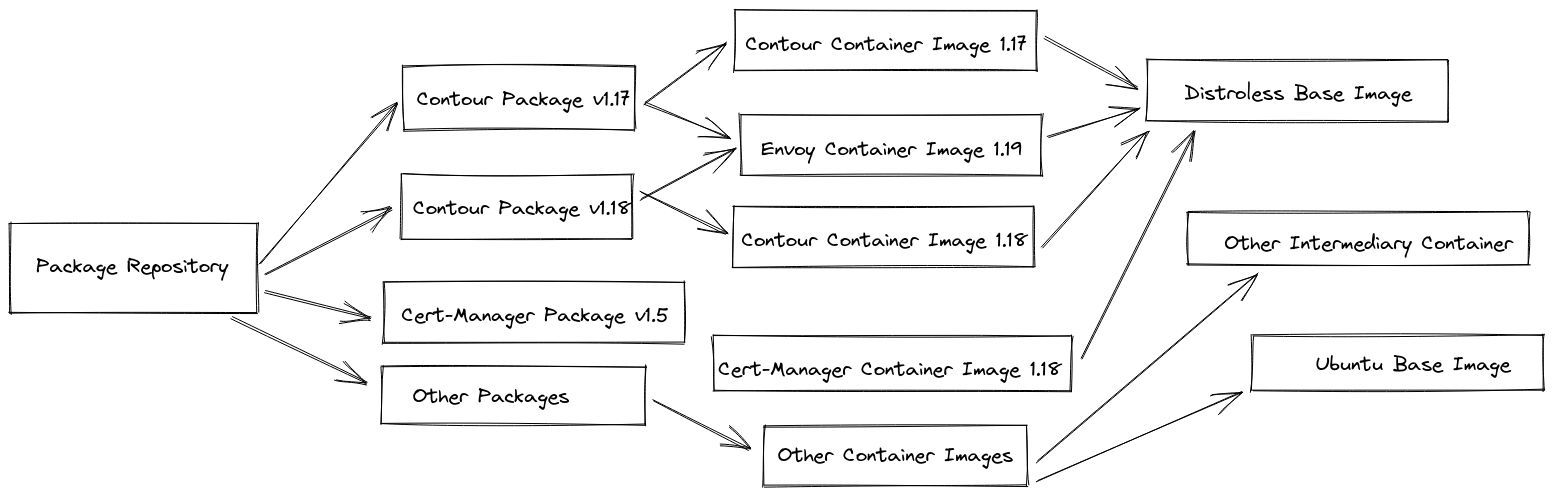
Managing workloads on many Kubernetes clusters with kapp-controller and Cluster API ¶
CReaTE leverages Cluster API to manage its clusters. Cluster API providers (running on a Kubernetes cluster) create additional Kubernetes clusters declaratively. These providers, running as applications on a management cluster, are given instructions from Custom Resources, which are stored as Kubernetes manifest files in the exact same manner as any Deployment, Secret, ConfigMap, etc. on top of Kubernetes. Custom Resources cause a significant amount of trouble for other deployment tools, but not for kapp.
Kapp is equipped with an extensive array of additional configuration. For example, rebaseRules allow you to verify continuous reconciliation of Cluster API Manifests is idempotent. Cluster API makes changes to the manifest files internally; Cluster API will sometimes update certain spec fields like a load balancer endpoint or which ports are opened into a network, and kapp needs to be informed on which fields might be modified by other resources. This means that if you want to scale a deployment to 5 nodes, kapp can do that declaratively, but if you want to turn on a node autoscaler, kapp will correctly merge that value so that Cluster API can use an autoscaler to increment the nodes itself. This is also important for the Army, since oftentimes we are unable to create our own underlying networking, and so we need the ability to sometimes declare that networking in the manifest files, while not losing the ability to access Cluster API values in the instances where we can leverage the provider’s own networking.
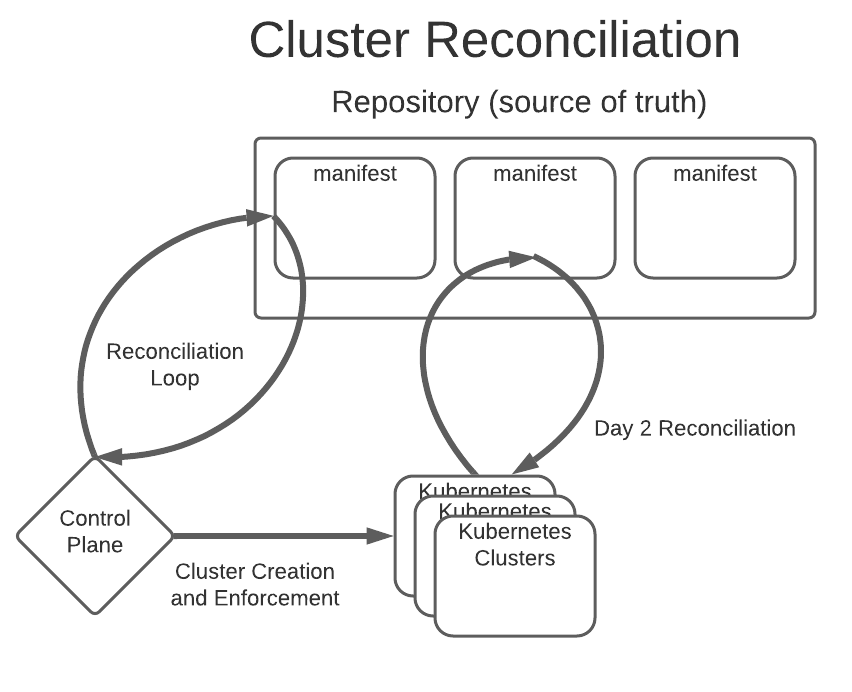
CReATE also needs to upgrade their machines very often, and while Cluster API natively supports that, the process for upgrading requires updating references in several Custom Resources, which are different depending on control plane machines or workload machines. Using kapp and Versioned Resources with templateRules we are able to turn the underlying MachineTemplate in Cluster API into something that is versioned, so when a machine is upgraded instead of attempting to mutate the immutable resource (which would fail), kapp instead makes a new versioned resource and updates the references in either the KubeadmControlPlane or MachineDeployment.
securidy-control-plane-ver-1 81d
securidy-control-plane-ver-10 11d
securidy-control-plane-ver-2 78d
securidy-control-plane-ver-3 77d
securidy-control-plane-ver-4 77d
securidy-control-plane-ver-5 73d
securidy-control-plane-ver-6 70d
securidy-control-plane-ver-7 58d
securidy-control-plane-ver-8 34d
securidy-control-plane-ver-9 12d
securidy-md-c-ver-1 81d
securidy-md-c-ver-10 11d
securidy-md-c-ver-2 78d
securidy-md-c-ver-3 77d
securidy-md-c-ver-4 77d
securidy-md-c-ver-5 73d
securidy-md-c-ver-6 70d
securidy-md-c-ver-7 58d
securidy-md-c-ver-8 34d
securidy-md-c-ver-9 12d
apiVersion: controlplane.cluster.x-k8s.io/v1alpha3
kind: KubeadmControlPlane
metadata:
name: securidy-control-plane
namespace: tools
spec:
infrastructureTemplate:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
kind: AWSMachineTemplate
name: securidy-control-plane-ver-10
namespace: tools
Kapp-controller in the App CR can authenticate to Kubernetes through two different methods: a service account name in the current cluster or using a kubeconfig to access a remote cluster. Cluster API also requires a kubeconfig to access the remote clusters and verify that they are healthy and to utilize some additional capabilities like autoscaling. The format of the kubeconfig file that Cluster API uses is the same format that kapp-controller requires, and so immediately after creating a new cluster kapp-controller can install new applications into this cluster. This helps install mandatory components like cluster networking, since kapp-controller would be unable to run on the workload cluster otherwise.
Using kapp’s ordering we are able to create a cluster, install cluster networking on it, install kapp-controller on the workload cluster, install common applications that help make Kubernetes production-ready (like encrypted storage classes, logging, audit, metrics, DNS, certificate management, and so on). This is done by using a series of App CR with the correct ordering applied, some of them running from the management cluster and otherwise localized to the workload cluster so that other teams can see and manage the health of those App CR. If the App CR is dependent on secrets or decryption keys located on the management cluster it can run there, otherwise it can execute on the workload cluster, regardless the visibility of the App CR can inspect into those resources and report back on their health.
apiVersion: kappctrl.k14s.io/v1alpha1
kind: App
metadata:
name: afc-sofac-harbor-postcreate
annotations:
kapp.k14s.io/change-group: create.army.mil/cni
kapp.k14s.io/change-rule: upsert before upserting create.army.mil/kapp-controller
# ...
---
apiVersion: kappctrl.k14s.io/v1alpha1
kind: App
metadata:
name: afc-sofac-harbor-kapp-controller
annotations:
kapp.k14s.io/change-group: create.army.mil/kapp-controller
kapp.k14s.io/change-rule.1: delete before deleting create.army.mil/cni
# ...
---
apiVersion: kappctrl.k14s.io/v1alpha1
kind: App
metadata:
name: afc-sofac-harbor-common-apps
annotations:
kapp.k14s.io/change-group: create.army.mil/foundation-common
kapp.k14s.io/change-rule.1: delete before deleting create.army.mil/kapp-controller
kapp.k14s.io/change-rule.2: upsert after upserting create.army.mil/kapp-controller
# ...
---
apiVersion: kappctrl.k14s.io/v1alpha1
kind: App
metadata:
name: afc-sofac-harbor-apps
annotations:
kapp.k14s.io/change-group: create.army.mil/foundation-stack
kapp.k14s.io/change-rule.1: delete before deleting create.army.mil/kapp-controller
kapp.k14s.io/change-rule.2: upsert after upserting create.army.mil/kapp-controller
kapp.k14s.io/change-rule.3: delete before deleting create.army.mil/foundation-common
kapp.k14s.io/change-rule.4: upsert after upserting create.army.mil/foundation-common
# ...
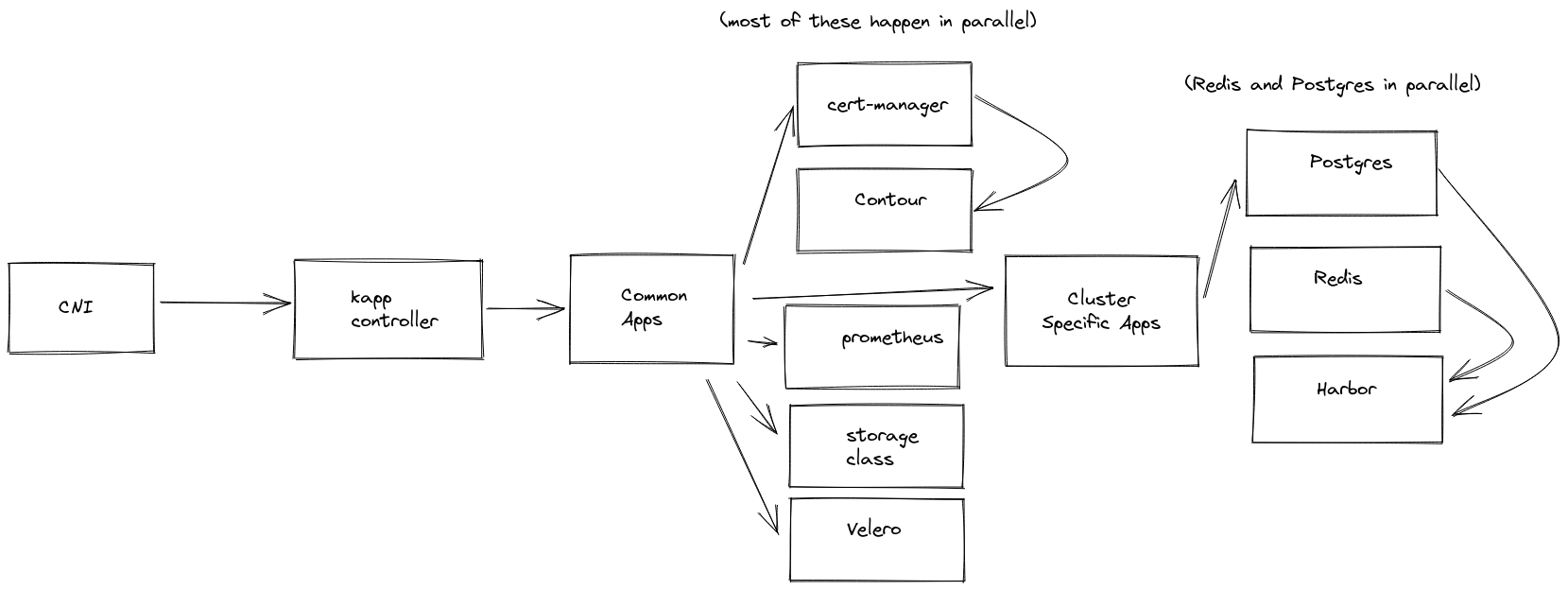
Results ¶
Increased developer and operator productivity ¶
Due to the fact that everything is maintained in templates and declarative objects - from the clusters and the CReATE platform to the applications - the platform operations team has been able to add new clusters and support new capabilities with ease. New cluster creation, full populated with common applications like cert-manager, Prometheus, fluent-bit, external-dns, occurs in less than 25 minutes. We are able to upgrade hundreds of VMs in under an hour, and do so multiple times a month, across numerous environments. Clusters are able to scale up and add new nodes in less than 5 minutes.
If an eye is turned towards the application developers, the most recent application teams have been able to be onboarded into the development environment in 90 minutes. This is massive and mirrors the efficiencies you’d expect from a modern platform all enabled, in large part, by the many layers of benefits from the Carvel tooling.
Faster path to production with safety ¶
Secure Software Supply Chain efforts are still nascent and in their juvenile stages across all sectors, but by leveraging imgpkg and the Carvel tooling the U.S. Army team has made a not-small step towards having a better understanding of what is running in their environments while also creating a simple mechanism to propagate changes to any and all environments at the drop of a dime.
MySquad, a Soldier-led application which enables squad leaders to support and enable their squads through sponsorship and task management, was created by the Army Software Factory for the Sergeant Major of the Army. The application developers on the team are able to push new changes to production in under 18 minutes, going through a DevSecOps pipeline that includes Carvel tooling. This results in rapidly bringing new features to the application that helps squad leaders build a more cohesive team.
Managing multi-clusters with ease ¶
As mentioned in the increased productivity result, creating clusters is rapid and less error-prone in the ECMA environment using the capabilities that CReATE has helped to build. Maintaining the clusters for upgrades also requires less toil, with the ability to push changes to applications like cert-manager, Contour, and others existing across dozens of clusters from a centralized source of truth that can be replicated (as mentioned here) to many different environments quickly.
Applying manifests to all clusters is one thing, but additionally, the team is able to roll out specific upgrades to critical capabilities installed on a single cluster, like Harbor or kpack. Harbor serves up containers for multiple application development teams, and Harbor itself is dependent on secondary systems like PostgreSQL and Redis. The team is able to upgrade these specific clusters, in an automated fashion, without introducing downtime to the services they provide.
Because of these results, CReATE is also able to support elements of Army Materiel Command (AMC), Army Forces Command (FORSCOM), Army Training and Doctrine Command (TRADOC), and is iterating towards helping all legacy software development efforts throughout the Department of Defense (DoD).
Join the Carvel Community ¶
We are excited to hear from you and learn with you! Here are several ways you can get involved:
- Join Carvel’s slack channel, #carvel in Kubernetes workspace, and connect with over 1000+ Carvel users.
- Find us on GitHub. Suggest how we can improve the project, the docs, or share any other feedback.
- Attend our Community Meetings! Check out the Community page for full details on how to attend.
We look forward to hearing from you and hope you join us in building a strong packaging and distribution story for applications on Kubernetes!